Llama
- causal LM: 严格遵守只有后面的token才能看到前面的token的规则
- 使用 RoPE 位置编码
Llama2
- 开发并发布了 Llama 2,包含预训练的大语言模型和微调大语言模型,模型规模有 7b、13b、70b 这三种(还有个没有开源的 34b 版本)
- 预训练语料增加了 40%
- context length 从 2048 提升到 4096
- 70b模型使用了 grouped-query attention (GQA)
- 提供了微调版本的 LLM,称为 Llama 2-Chat,针对对话用例进行了优化
- Llama2 在大多数基准测试中都优于开源聊天模型,并且基于有用性和安全性方向进行人工评估,期望称为封闭源模型(chatgpt等)的合适替代品
- 提供了对 Llama 2-Chat 微调和安全改进的方法的详细描述,为开源社区做出贡
Llama3
- llama3 与 llama2 的模型架构完全相同,只是 model 的一些配置(主要是维度)有些不同,llama2 推理的工程基本可以无缝支持 llama3
- llama3-8B 相比于 llama2-7B 的模型参数变化原因:
- vocab_size:32000 ->128256。词汇表的扩大,导致 embedding 参数的增大 (128256-32000)40962 Byte=752MB,另外模型最后一层 lm_head 的输出维度就是 vocab_size,所以 lm_head 的参数同样增大 752MB,总计带来模型增大 1504MB
- max_position_embeddings:4096->8192。也即 context window 扩大了,训练时输入的序列长度增大,推理能支持的序列长度增大,没有实际计算的差别。
- num_key_value_heads:32 -> 8。即使用了 GQA,因为 num_attention_heads 维持32,也就是计算时 key、value 要复制 4 份。参数量会下降,K_proj、V_proj 的参数矩阵会降为 llama2-7B 的 1/4,共计减少 32 * 4096 * 4096 * 2 * 2 / 4 * 3 Byte(1536MB)
- intermediate_size:11008->14336。只是 FFN 时的中间维度变了,计算范式不变。参数量增大:32 * 4096 * (14336-11008) * 3 * 2 / 1024 / 1024 Byte (2496MB)
- 综上:通过以上几个设置和维度的变化,最终带来模型增大了2464M,这也是7B->8B的原因,本质上的计算模式没有变化
- 效果提升主要是数据工程
- 数据量:预训练 llama3 用了超15T token(来自公开可获取的来源),是llama2的7倍多,其中代码相关的数据是llama2的4倍多;Fine-tuning阶段的数据除了公开能获取的 instruction datasets, 还有自己制作的超过1千万人工标注 examples。
Llama4
预训练
- Llama 系列首次引入了 Mixture-of-Experts (MoE,专家混合) 架构,MoE 的核心思想是拥有多个“专家”子模型,在处理每个输入时仅激活一部分参数,从而大幅提升参数规模却不显著增加推理开销
- 提出了 iRoPE (interleaved RoPE),部分层使用了 NoPE,即不使用 rope 作为位置编码,另外大部分层使用 RoPE 进行编码。另外采用了 inference time temperature scaling 来提升长文本泛化能力
- 使用 30 万亿标记的训练数据,涵盖 200 种语言,其中超过 100 种语言的标记数超过 10 亿,相比 Llama 3 的 15 万亿标记翻倍
后训练:包括监督微调(SFT)、在线强化学习(RL)和直接偏好优化(DPO),特别针对推理、编码和数学问题进行优化。SFT 和 DPO 使用小规模训练的原因是发现 SFT 和 DPO 会过度约束模型,限制了在线 RL 阶段的探索。后训练分为三个阶段:
- 小规模 SFT:删除了 50% 的 easy 难度数据
- 在线强化学习(RL)
- 小规模直接偏好优化(DPO):解决模型回复质量问题,在模型智能程度与对话能力之间取得平衡
Llama4 的三个不同规模大小的模型
| 模型 | 活跃参数 | 总参数 | 专家数 | 上下文窗口 | 备注 |
|---|---|---|---|---|---|
| Scout | 17B | 109B | 16 | 10M | 适合单 GPU 运行,性能优于 Gemini 2.0 Flash-Lite |
| Maverick | 17B | 400B | 128 | 未指定 | 性能优于 GPT-4o,成本效益高 |
| Behemoth | 288B | ~2T | 16 | 未指定 | 仍在训练中,预计超越 GPT-4.5 等模型 |
- Scout:活跃参数 17 亿(17B),总参数 1090 亿(109B),16 个专家,上下文窗口达 1000 万标记(10M)。它能运行在单个 NVIDIA H100 GPU 上,适合资源有限的用户。
- Maverick:活跃参数 17 亿,总参数 4000 亿(400B),128 个专家,性能表现优于 GPT-4o 和 Gemini 2.0 Flash,成本效益高。
- Behemoth:活跃参数 2880 亿(288B),总参数约 2 万亿(~2T),16 个专家,目前仍在训练中,预计在数学、多语言和图像基准测试中表现卓越。
ChatGLM and ChatGLM2
- ChatGLM
- 使用 prefix LM:prefix部分的token互相能看到
- 使用 RoPE 位置编码
- ChatGLM2
- 回归 decoder-only 结构,使用 Causal LM
- 使用 RoPE 位置编码
Bloom
- 176B 参数,decoder only
- BLOOM 使用 Alibi 位置编码
- ROOTS语料库上训练,该数据集包括46种自然语言和13种编程语言(共59种)的数百个来源
InternLM-XComposer
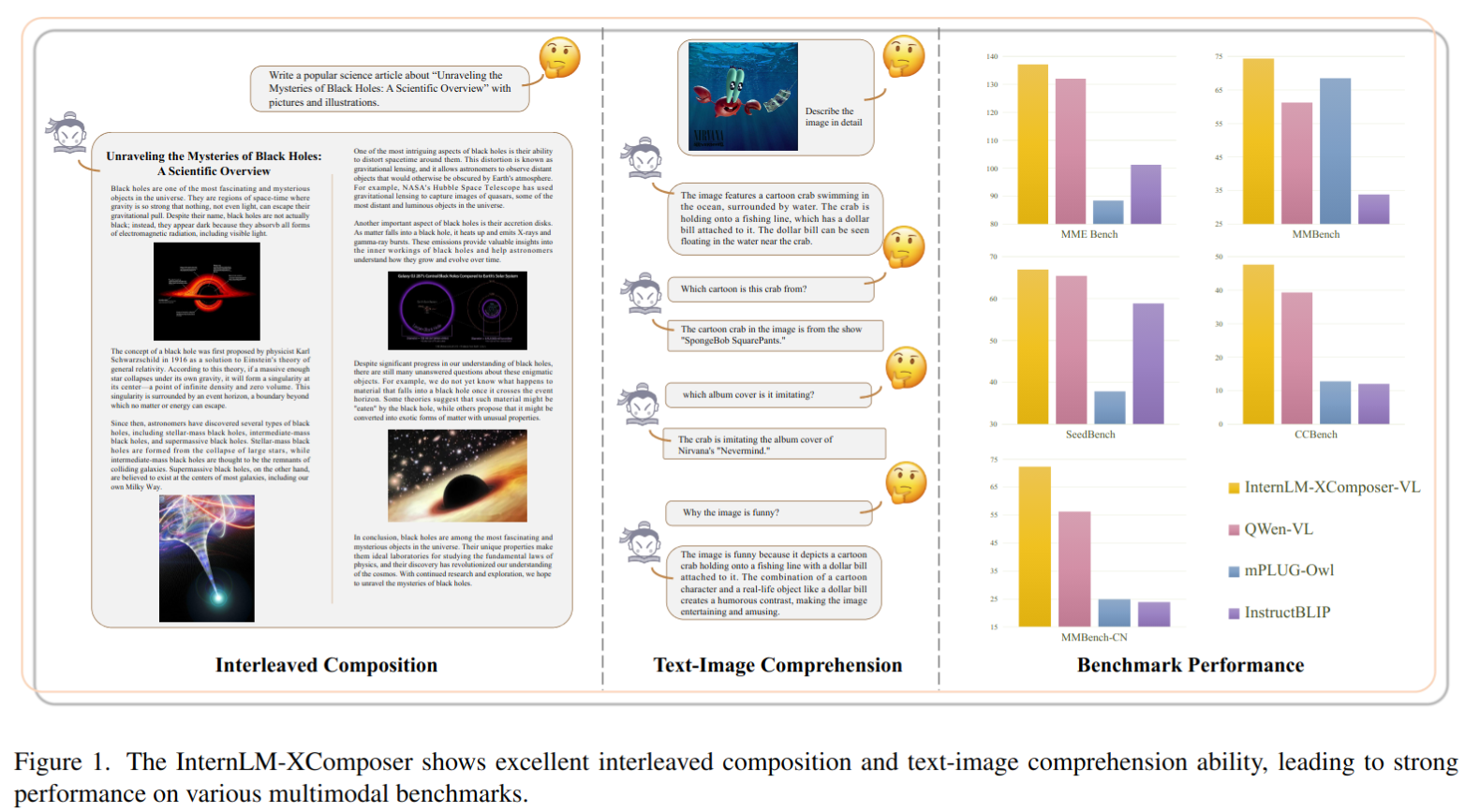
- 提出了视觉语言大模型 InternLM-XComposer,具有高级的文本图像理解和组合能力
- 交错式文本-图像组合:InternLM-XComposer 擅长生成与上下文相关图像交错的长篇内容,从而提升了视觉-语言交互的体验。
- 首先根据人工提供的指令创建文本
- 随后,它自动确定文本中最适合放置图像的位置,并提供相应的合适的图像描述。根据生成的描述,与依赖于文本-图像生成模型来帮助的方法不同,我们选择从大规模网络爬取的图像数据库中获取对齐的图像,以实现更真实的质量和上下文对齐。此外,它还提供了灵活性,允许用户自定义图像库。
- 与仅依赖于 CLIP 进行图像检索的基线方法相比,XComposer 提供了更可靠的选择最合适图像的解决方案。首先,使用 CLIP 从数据库中选择潜在的图像候选项。然后,InternLM-XComposer 利用其理解能力来识别最适合内容的图像
- 具有丰富多语言知识的理解。LLM 在处理开放世界任务方面表现出了出色的通用性,这一能力归因于其广泛的训练数据,例如 LLaMA2 中使用的 2T token 训练。这一庞大数据集囊括了多个领域的广泛语义知识。相比之下,现有的视觉-语言数据集在容量和多样性方面相对受限。为了解决这些限制,我们采用了两种实际解决方案:
- 首先,从公共网站收集了一个包含超过 1100 万个语义概念的交错多语言视觉-语言数据集
- 其次,在训练流程中精心制定了预训练和微调策略,采用了主要是英文和中文的纯文本和图像-文本混合训练数据。因此,InternLM-XComposer 在理解各种图像内容和提供广泛的多语知识方面表现出了出色的能力。
- 交错式文本-图像组合:InternLM-XComposer 擅长生成与上下文相关图像交错的长篇内容,从而提升了视觉-语言交互的体验。
- 所提出的 InternLM-XComposer 在文本-图像理解和组合方面表现出卓越的能力。它在各种领先的视觉-语言大型模型的基准测试中取得 SOTA 的成绩,包括英文的 MME 基准测试、MMBench、Seed-Bench 以及中文的 MMBench-CN 和 CCBench(中国文化基准测试)的评估。值得注意的是,我们的方法在中文语言的基准测试中,即MMBench-CN 和 CCBench 上显著优于现有框架,展示出卓越的多语知识能力。
CODEFUSION
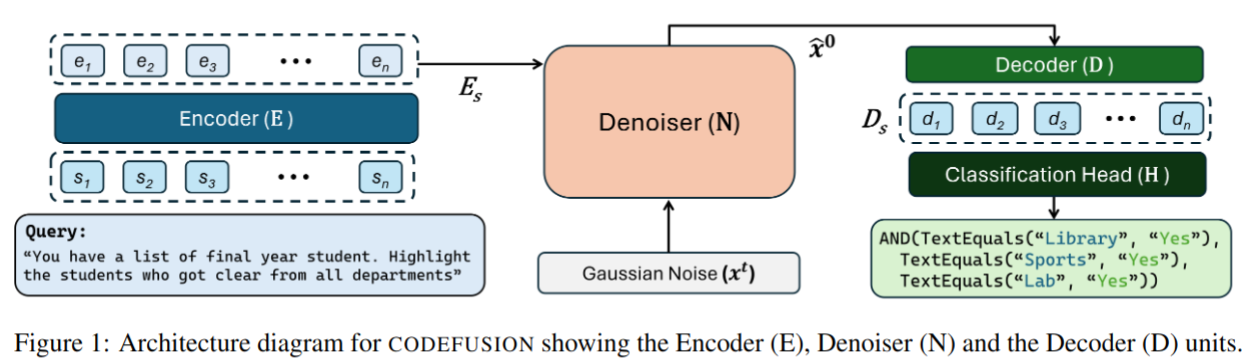
- 提出了 CODEFUSION,一个自然语言到代码(NL-to-code)的生成模型
- 它结合了编码器-解码器架构(Raffel et al., 2020)与扩散过程。编码器将自然语言映射为连续表示,扩散模型使用这一表示作为额外条件来去噪随机高斯噪声输入。为了生成语法正确的代码,我们随后将去噪后的嵌入输入到 transformer 解码器,通过完整的自注意力和与嵌入话语的交叉注意力,获得代码 token 的概率分布。最后,我们在每个索引选择最高概率的 token。
- 为了预训练 CODEFUSION 进行代码生成,我们将连续段落去噪(CPD)任务扩展到代码领域。具体来说,我们只对代码中对应于标识符或目标语言内置关键词的 token 应用噪声。这个去噪任务使模型能够学习关键代码 token(如变量名、函数名和控制流内置函数)之间的关系。
- 我们发现,与自回归模型相比,CODEFUSION 产生了更多样化的代码(n-gram 比例更高,嵌入相似性更低,编辑距离更高)。CPD 目标,它使模型偏向于学习以语境感知的方式去除噪声,并配以能够访问完整去噪表示的解码器,共同使 CODEFUSION 在与 GENIE 比较时(一个文本扩散模型),生成了 48.5% 更多语法正确的代码(平均跨三种语言)。我们在三种不同语言的自然语言到代码上评估 CODEFUSION:Python,Bash 和 Microsoft Excel 中的条件格式化规则。我们的结果表明,CODEFUSION的(7500万参数)top-1 结果与更大的最新系统(3.5亿–1750亿参数)相当或更好。在 top-3 和 top-5 中,CODEFUSION 的表现优于所有基线。
baichuan2
- 本文提出了 Baichuan2
- 提出 baichuan2-7b 和 baichuan2-13b,这两个模型都是在2.6万亿令牌上进行训练的,比 Baichuan 1 的数据集大了一倍多。
- 在像 MMLU、CMMLU 和 C-Eval 等一般基准上,Baichuan 2-7B 的性能比 Baichuan 1-7B 提高了近 30%。具体来说,Baichuan 2 优化了数学和代码问题的性能
- GSM8K 和 humaneval 几乎涨点一倍
- 在医疗和法律上也有提升,比如 MedQA 和 JEC-QA 数据集
- 在像 MMLU、CMMLU 和 C-Eval 等一般基准上,Baichuan 2-7B 的性能比 Baichuan 1-7B 提高了近 30%。具体来说,Baichuan 2 优化了数学和代码问题的性能
- 提出 Baichuan 2-7B-Chat 和 Baichuan 2-13B-Chat,经过微调后的对话模型
- 为了推动研究合作和持续改进,还发布了 Baichuan 2 在各个训练阶段的检查点,从 2000 亿 token 到完整的 2.6 万亿 token
- 分享一些通过训练 Baichuan 2 获得的试验、错误和经验教训
- 提出 baichuan2-7b 和 baichuan2-13b,这两个模型都是在2.6万亿令牌上进行训练的,比 Baichuan 1 的数据集大了一倍多。
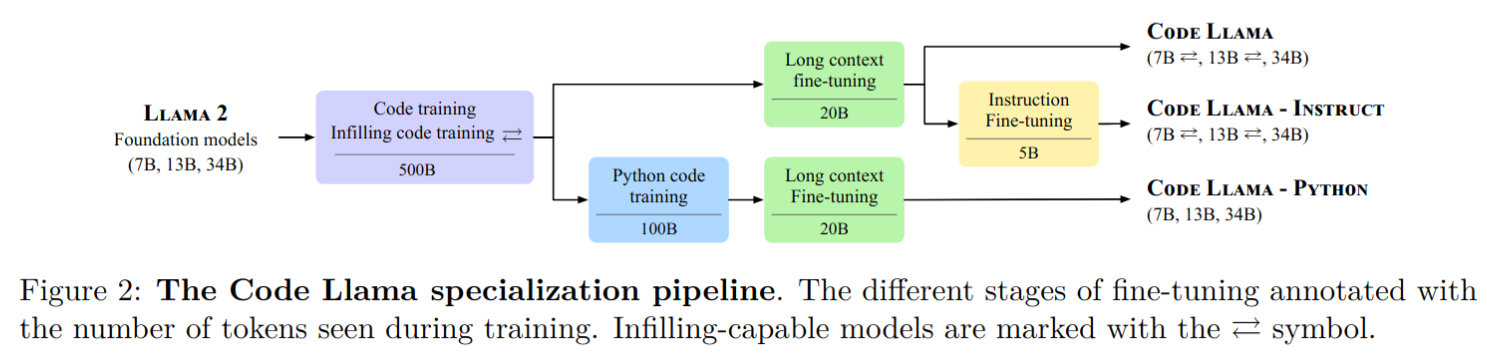
Code Llama
- 发布了 Code Llama,基于 Llama 2 的一系列大型代码语言模型,提供了在开放模型中的最先进性能、填充能力、支持大输入上下文以及零-shot编程任务指令跟随能力。
- 提供多个版本以涵盖各种应用:
- 基础模型(Code Llama)
- Python 专业化版本(Code Llama - Python)
- 指令跟随模型(Code Llama - Instruct)
- 每个版本分别具有 7B、13B 和 34B 参数,所有模型都是在 16k token 序列上训练的,并在最多包含 100k token 的输入上进行长序列改进。
- 7B 和 13B 的 Code Llama 以及 Code Llama - Instruct 变种支持基于周围内容的填充。
- Code Llama 在多个代码基准测试中达到了开放模型中的最先进性能,分别在 HumanEval 和 MBPP 上取得了高达 53% 和 55% 的分数(优于 Llama2 70B),MultiPL-E 上精度优于所有开源模型
- 重点是和 Llama2 开源协议一样,Code Llama 开源并允许进行研究和商业用途
- 提供多个版本以涵盖各种应用:
- code llama 各系列模型训练流程如下: