Pattern-Exploiting Training(PET)
- 它通过人工构建的模版与 BERT 的 MLM 模型结合,能够起到非常好的零样本、小样本乃至半监督学习效果,而且该思路比较优雅漂亮,因为它将预训练任务和下游任务统一起来了
P-tuning
- P-tuning(GPT Understands, Too)
- P-tuning 重新审视了关于模版的定义,放弃了“模版由自然语言构成”这一常规要求,从而将模版的构建转化为连续参数优化问题,虽然简单,但却有效
- P-tuning直接使用[unused*]的token来构建模版,不关心模版的自然语言性
LoRA
- 低秩自适应 (Low-Rank Adaptation, LoRA):冻结了预训练的模型权重,并将可训练的秩分解矩阵注入到 Transformer 架构的每一层,极大地减少了下游任务的可训练参数的数量,有效提升预训练模型在下游任务上的 finetune 效率
【背景】之前的 PEFT 方法是 adapter/prefix/promp/P-tuning,但是Adapter会引入很强的推理延迟(只能串行),prefix/prompt/P-tuning很难练,而且要占用context length,变相的降低模型能力
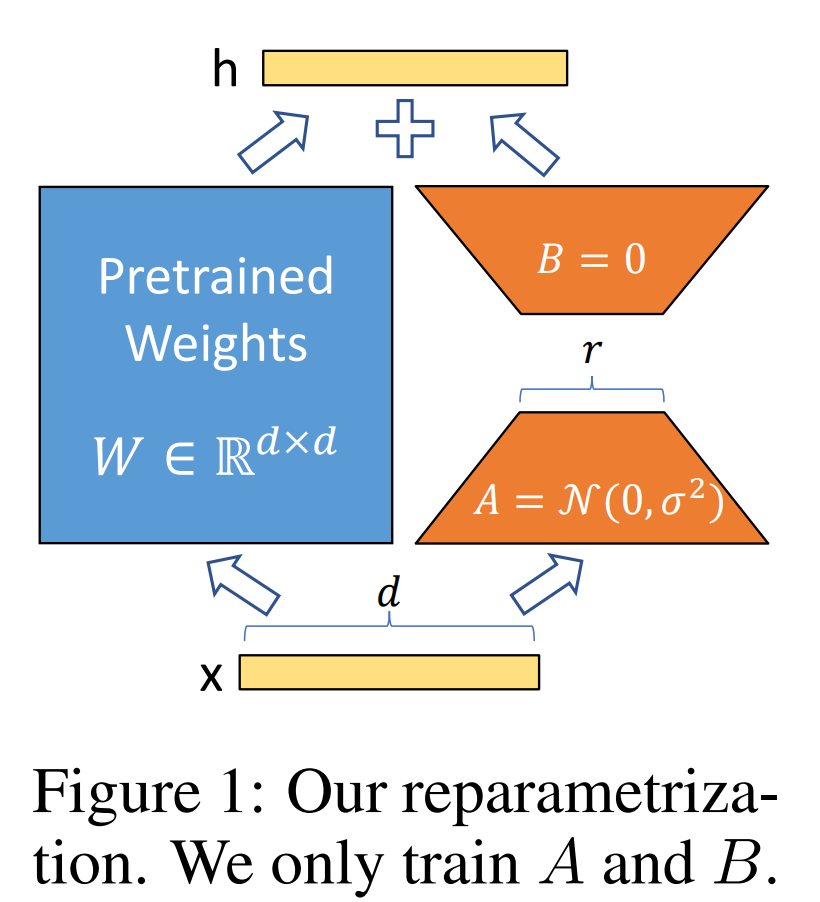
【详解】具体来说,就是考虑到语言模型(LLM 尤其如此)的参数的低秩属性(low intrinsic dimension),或者说过参数化,在做 finetune 的时候不做 full-finetune,而是用一个降维矩阵 A 和一个升维矩阵 B 去做 finetune。如果我们认为原来的模型的某个参数矩阵为
,那么可以认为原来经过全微调的参数矩阵为 ,但考虑到前面的低秩属性,在 lora 中我们可以简单认为 (B 是升维矩阵,A 是降维矩阵,其中 A 正常随机数初始化,B 全 0 初始化,从而保证训练初期的稳定性),其中 BA 的秩相当于是你认为的模型实际的秩。这样的话在做推理的时候, ,根本不会引入推理延迟,因为你只需要把训好的 lora 参数 加进模型初始权重 中就可以了。在 Transformer 中 self-attention 和 mlp 模块都有对应的 params 矩阵,对应加上 lora 即可。 - llama 为了节省参数量一般只加在 q、v 上 (参考),原论文实验是不会掉点
- bloom 一般加在 q、k、v 上
为什么 LoRA 使用 B 矩阵全 0 初始化而不是 A 矩阵全 0 初始化?
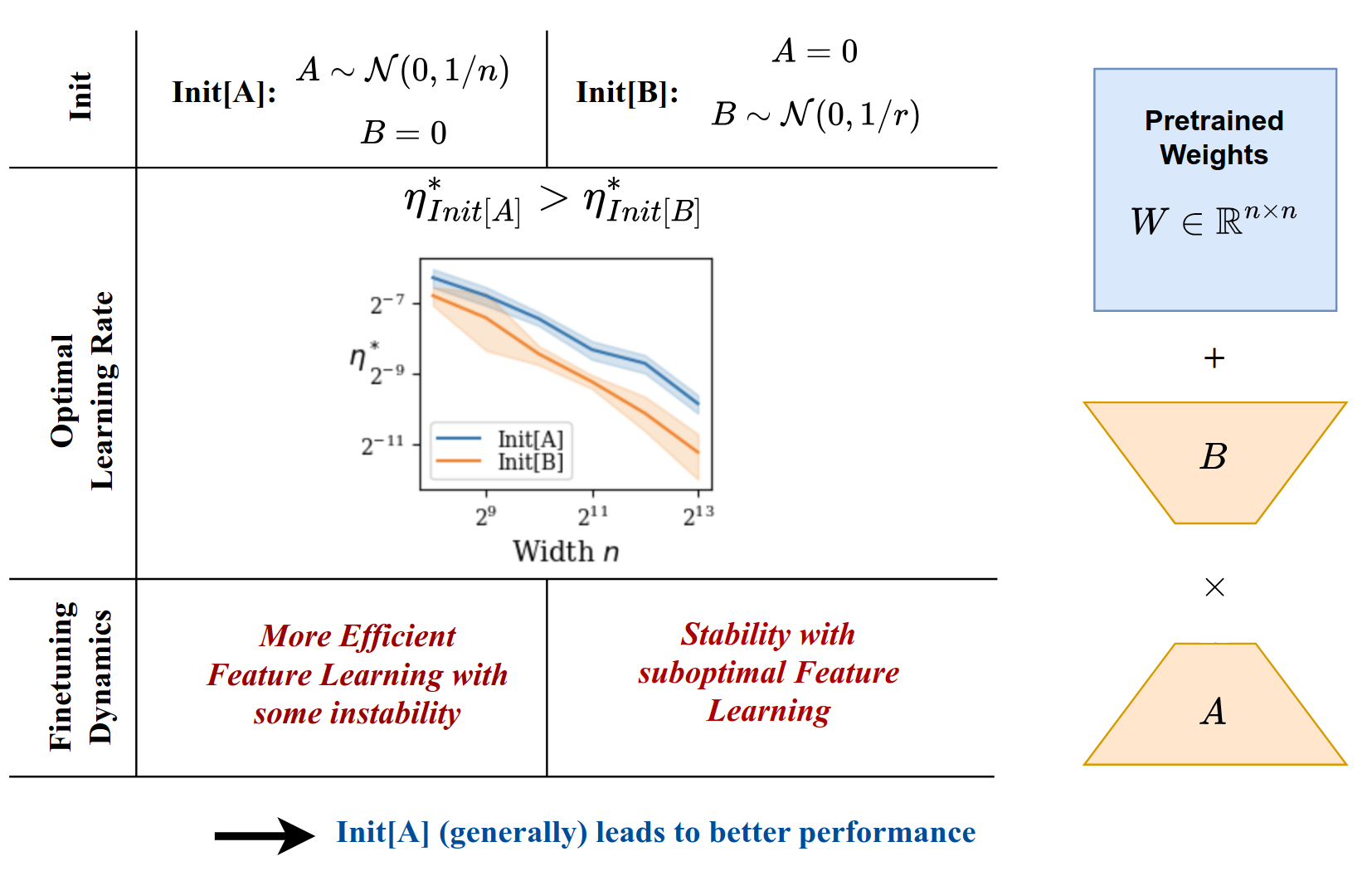
虽然理论上可以将 A 矩阵设置为 0(即 B 矩阵随机初始化),但研究表明这会导致次优性能。在论文 The Impact of Initialization on LoRA Finetuning Dynamics 中,作者比较了两种初始化方案:
- Init[A]:B 初始化为 0,A 随机初始化(标准 LoRA)。
- Init[B]:A 初始化为 0,B 随机初始化。
研究发现:
- Init[A] 允许更大的学习率(最大为
),相比之下 Init[B] 的学习率限制为 。这使得 Init[A] 在特征学习方面更高效,尽管可能存在“内部不稳定性”。 - Init[B] 更稳定,但 B 矩阵训练不足,导致性能较差。