📋 目录
🎯 引言
随着大语言模型(LLM)的迅速发展,越来越多的模型被用于辅助甚至主导编程任务。然而,大模型究竟在代码能力方面达到了怎样的水平?它们是否适合实际的软件工程场景?哪些模型更适合算法问题,哪些则在工程实现方面更为擅长?
本文围绕大模型的编程能力评估展开,结合两个具有代表性的公开评测榜单(LiveCodeBench 和 SWE-Bench),并以两个自构造的典型测试样例(小球物理模拟 + Triton 算子实现)作为补充,实测多个主流大模型的表现,包括 GPT-4o、Claude Sonnet 4、Gemini 2.5 Pro、Kimi K2、DeepSeek R1、豆包、Qwen3-235B 等。
📊 了解大模型的代码能力
🏆 LiveCodeBench: 测试算法能力
LiveCodeBench 是由加州大学伯克利分校、麻省理工学院和康奈尔大学的研究人员开发的先进评测基准。通过从 LeetCode、AtCoder 和 CodeForces 等竞赛平台实时收集新发布的编程问题,确保评测的无污染性(仅使用模型训练截止日期之后发布的问题),并涵盖代码生成、代码自修复(基于反馈调试代码)、代码执行以及测试输出预测等多种代码相关能力。
Leaderboards 网址: https://livecodebench.github.io/leaderboard.html
7/1/2024 - 2/1/2025 榜单
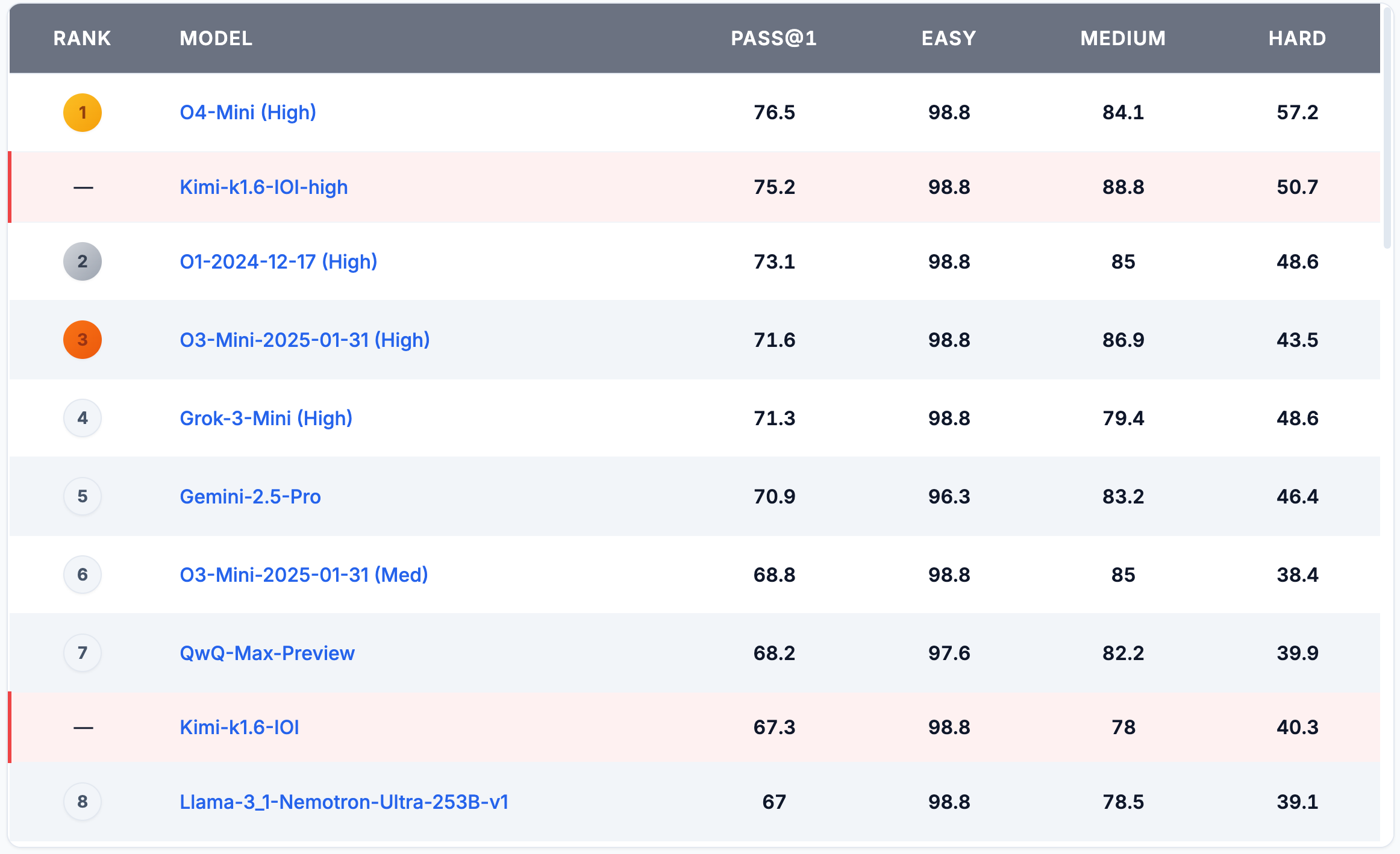
8/1/2024 - 5/1/2025 榜单
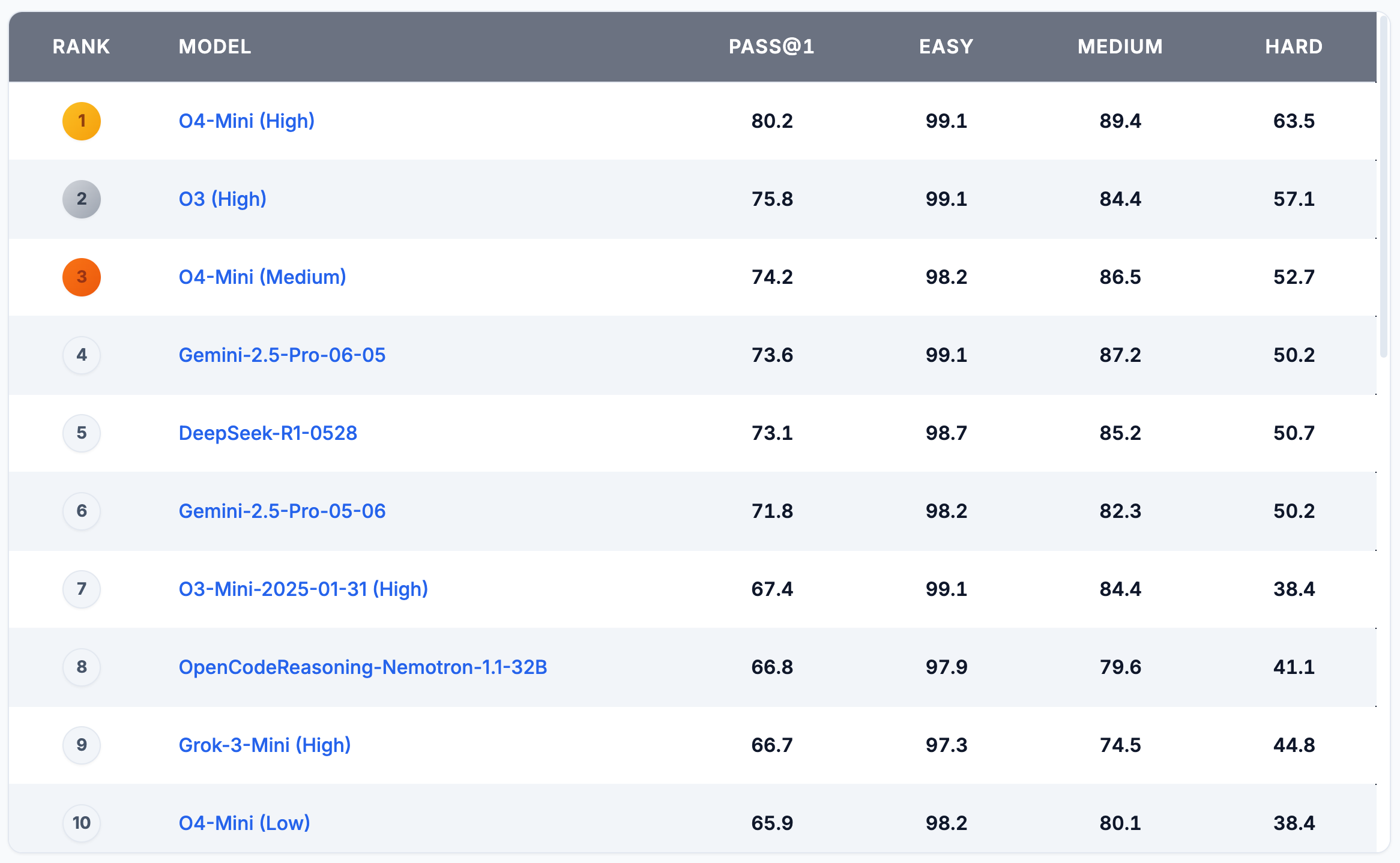
🔧 SWE-Bench: 测试工程能力
SWE-Bench(Software Engineering Benchmark)是由普林斯顿大学 NLP 团队于 2023 年 10 月提出,旨在评估大语言模型(LLM)解决真实软件工程问题(如 bug 修复和功能改进)的能力,而非传统算法题解决能力。
- 从 12 个流行的开源 Python 仓库中收集了 2,294 个任务实例,每个任务基于 GitHub issue 和对应 Pull Request(PR),要求模型生成代码补丁以解决问题,并通过仓库测试套件验证补丁的正确性
- SWE-Bench 被认为是最具挑战性的编程基准之一,因为它模拟了真实软件开发中的复杂场景
Leaderboards 网址: https://www.swebench.com/index.html
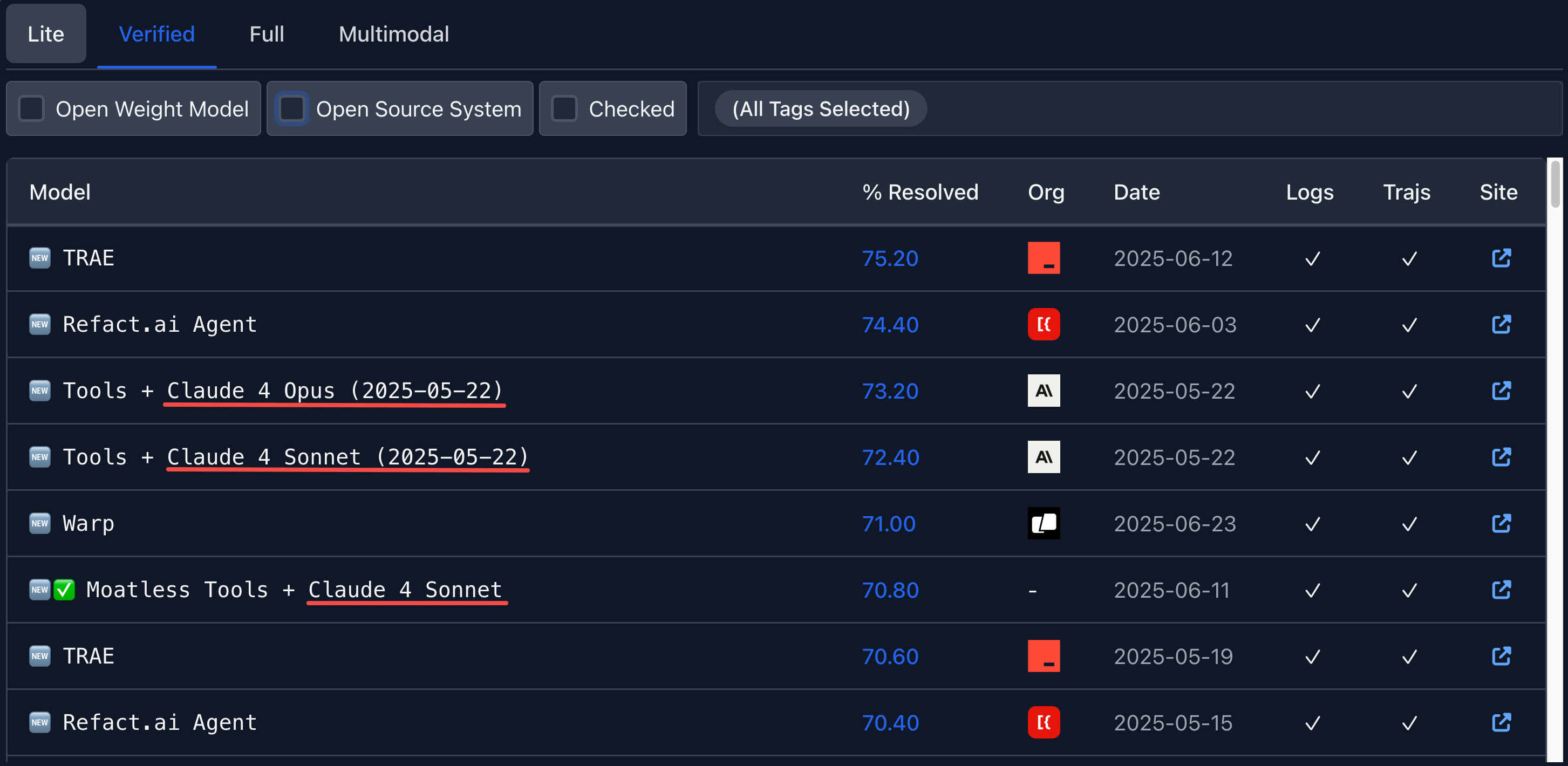
📈 Claude 的功能能力很强
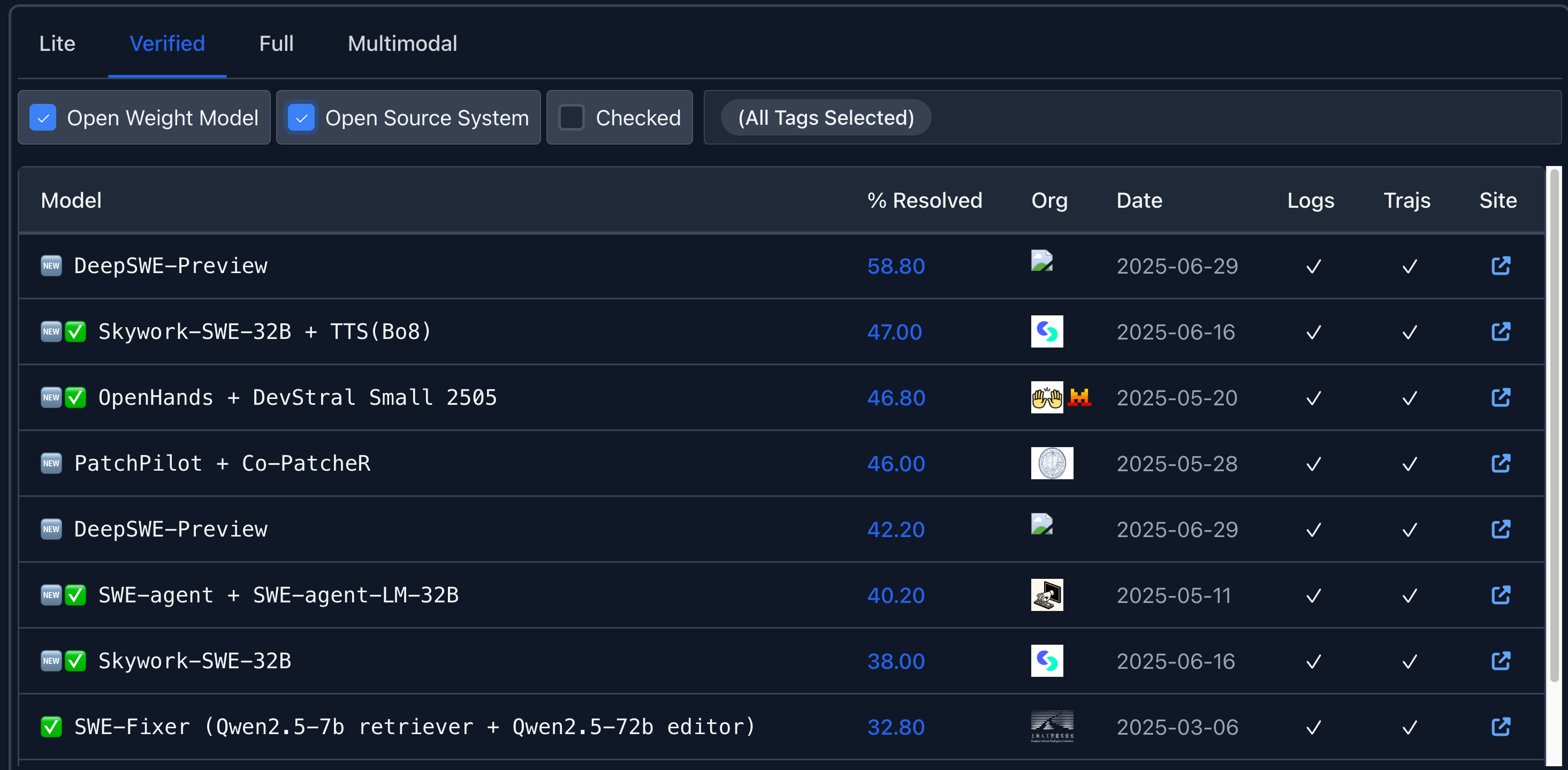
📉 开源模型仍有差距
🧪 自测样例
⚽ 经典小球测试样例
该样例可以方便测试人员肉眼观察代码实现效果,不需要懂代码的人也能通过代码运行结果来直观体会到模型的代码撰写能力。不过注意这个测试样例主要是用于简单验证大模型的代码编程能力,只能作为初步判断,不一定能完全体现出模型的能力。
🎯 测试Prompt:
编写一个 html 代码,模拟一个小球在匀速旋转的六边形内部弹跳的物理效果(包括重力、碰撞反作用力、摩擦力等)。球应该受到重力,在碰到六边形的内壁后会回弹,受到碰撞反作用力、摩擦力的影响。注意球的初始化位置在六边形内部的中心。
⚠️ 注意事项:
- 这里所有测试都取第一次的结果,不代表模型能达到的最优效果。比如 Kimi K2 模型在第一次运行失败,第二次运行成功
- 这个测试样例比较经典,不排除有部分模型会针对这个测试样例专门进行优化,所以能完成这个测试样例不代表模型能力一定很强,只能说至少应该是在基本能用的水平以上
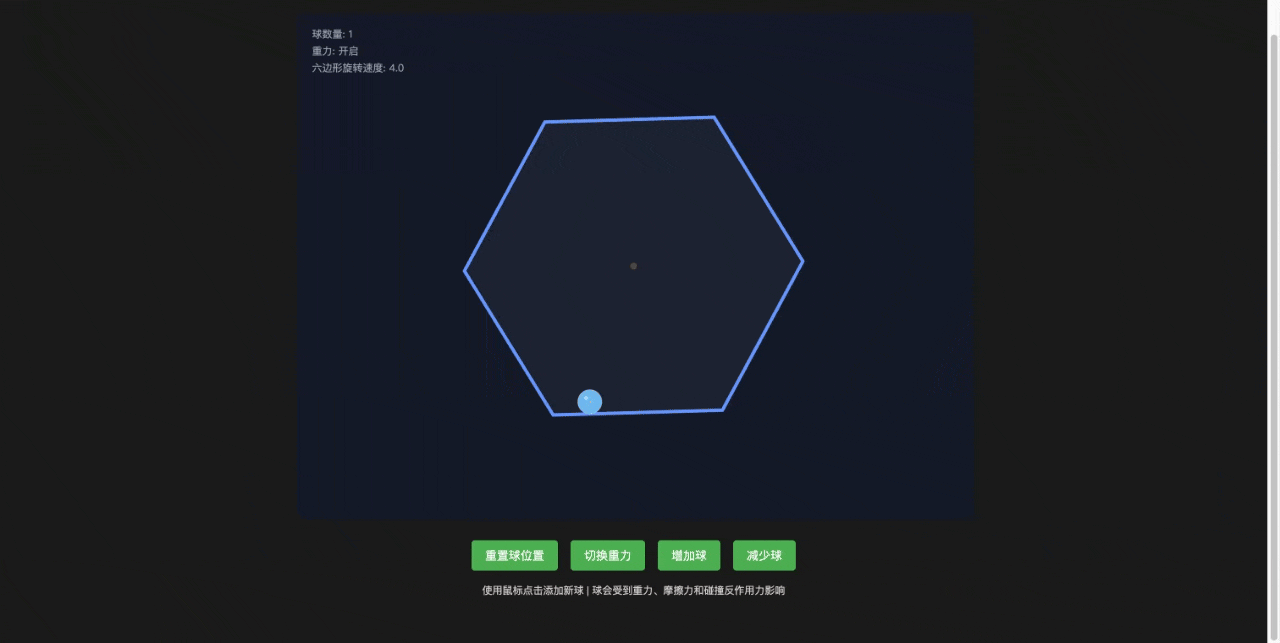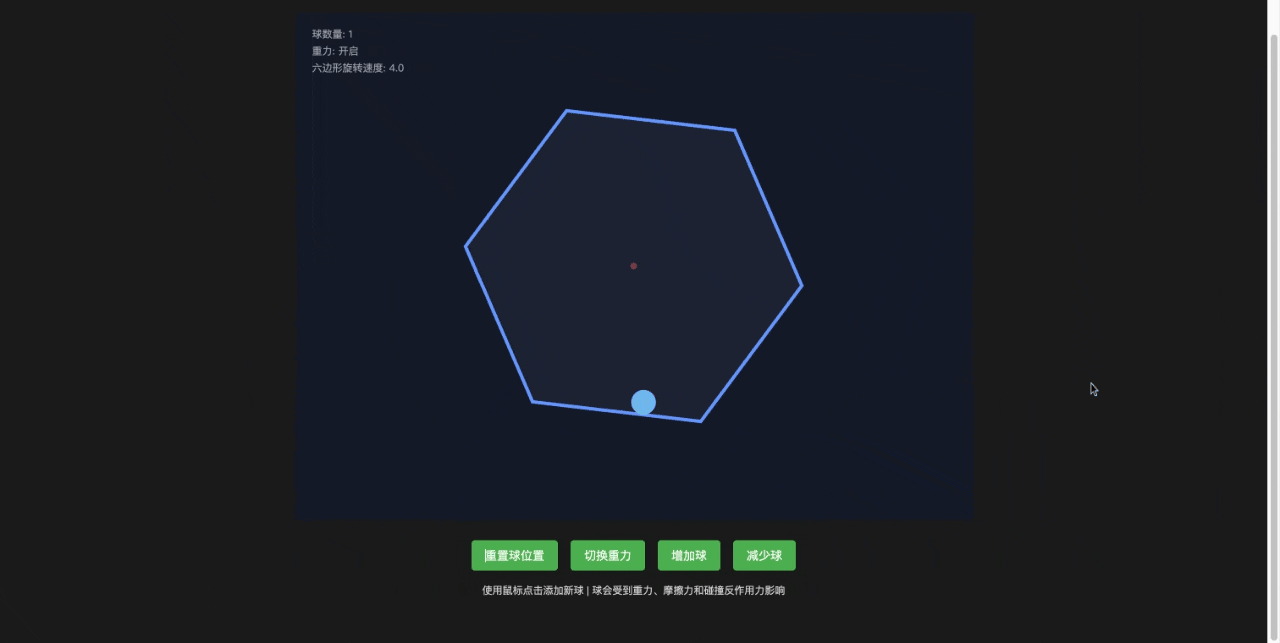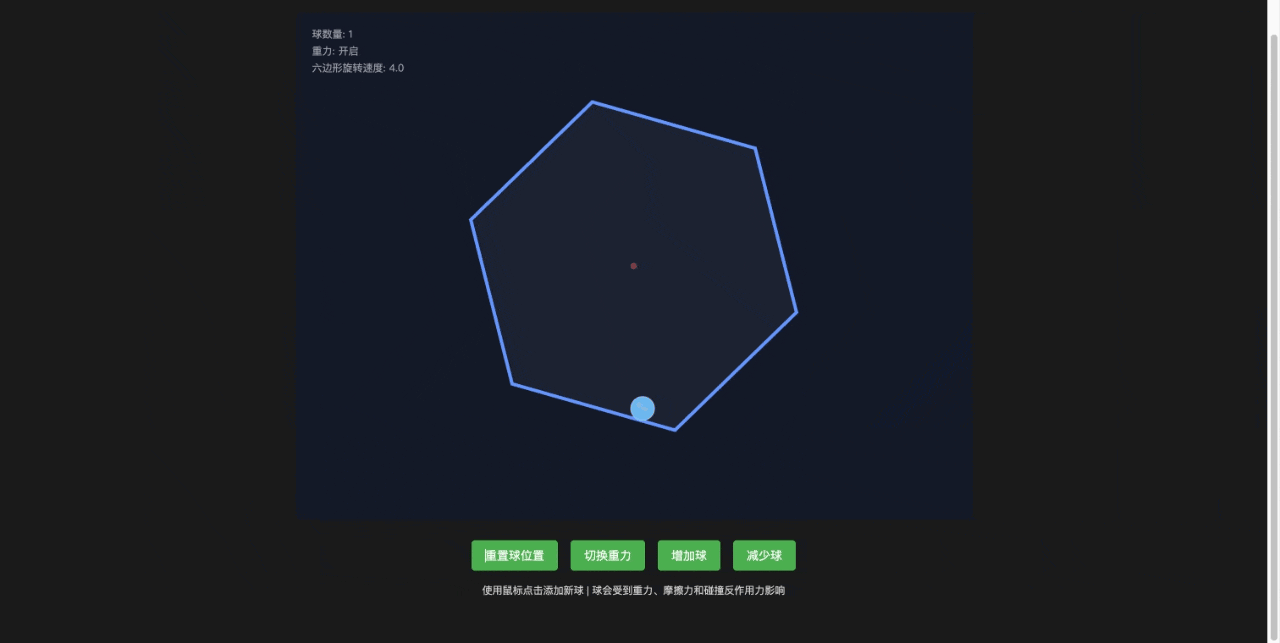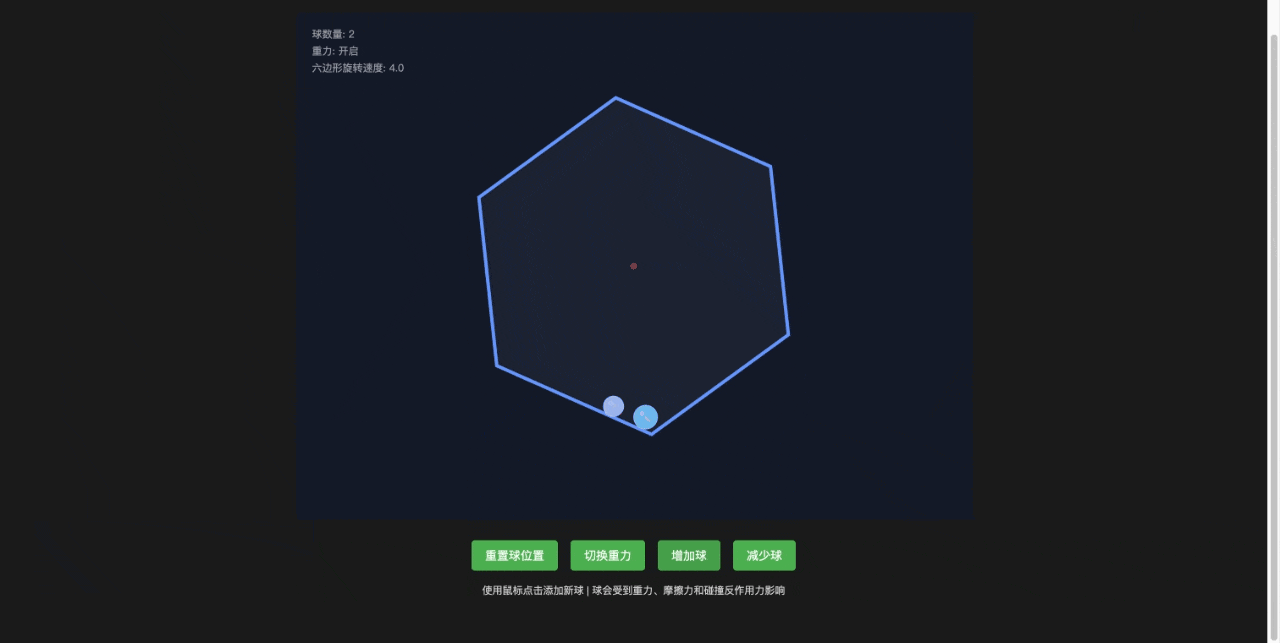
Claude Sonnet 4
基本合理,还额外增加了一些功能,比如增加小球和去掉小球
GPT-4o
完全错了,小球跳出了六边形
GPT o4-mini-high
基本合理
Grok 4
完全错了,六边形都没有成功画出来
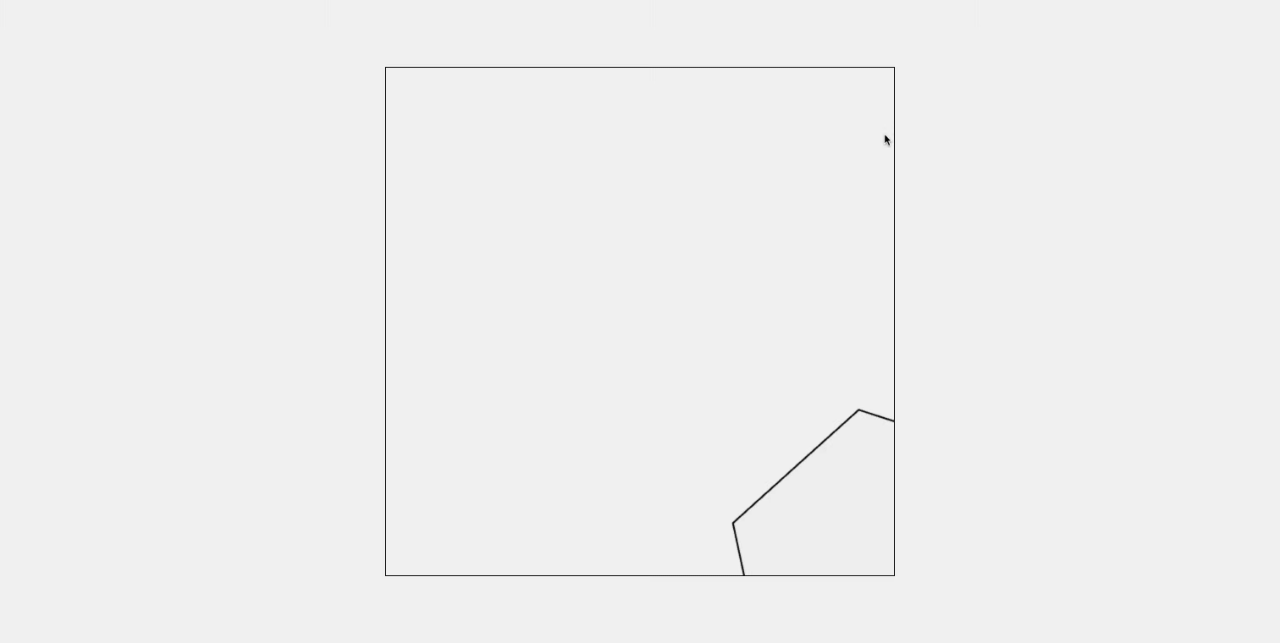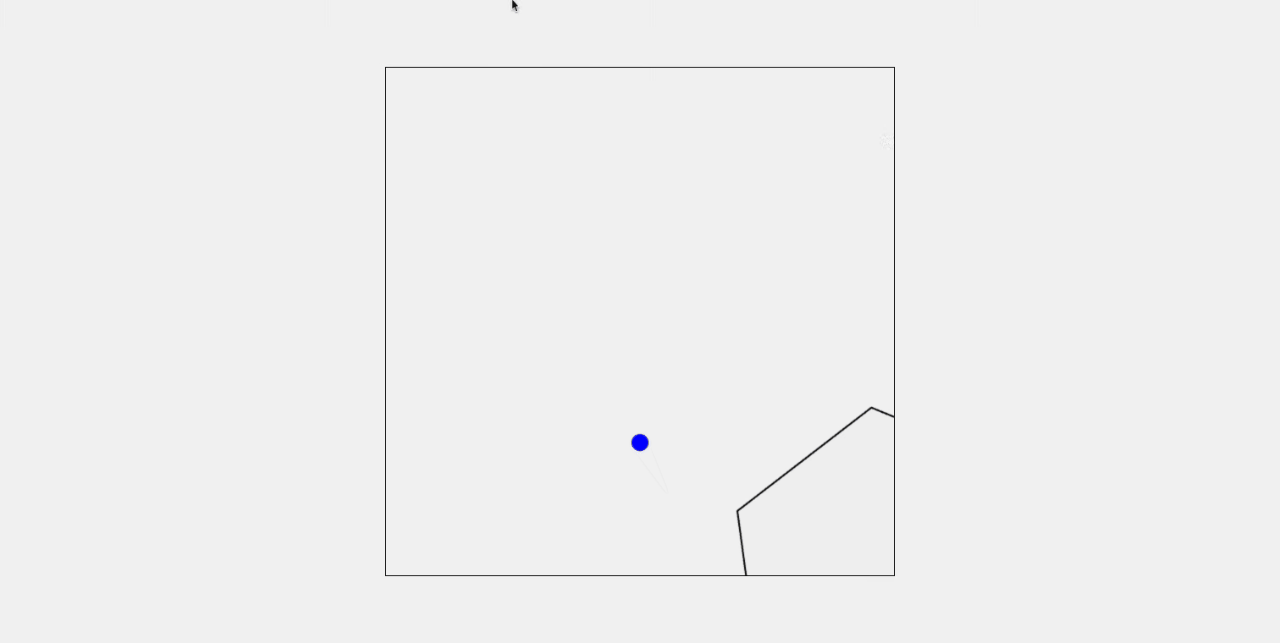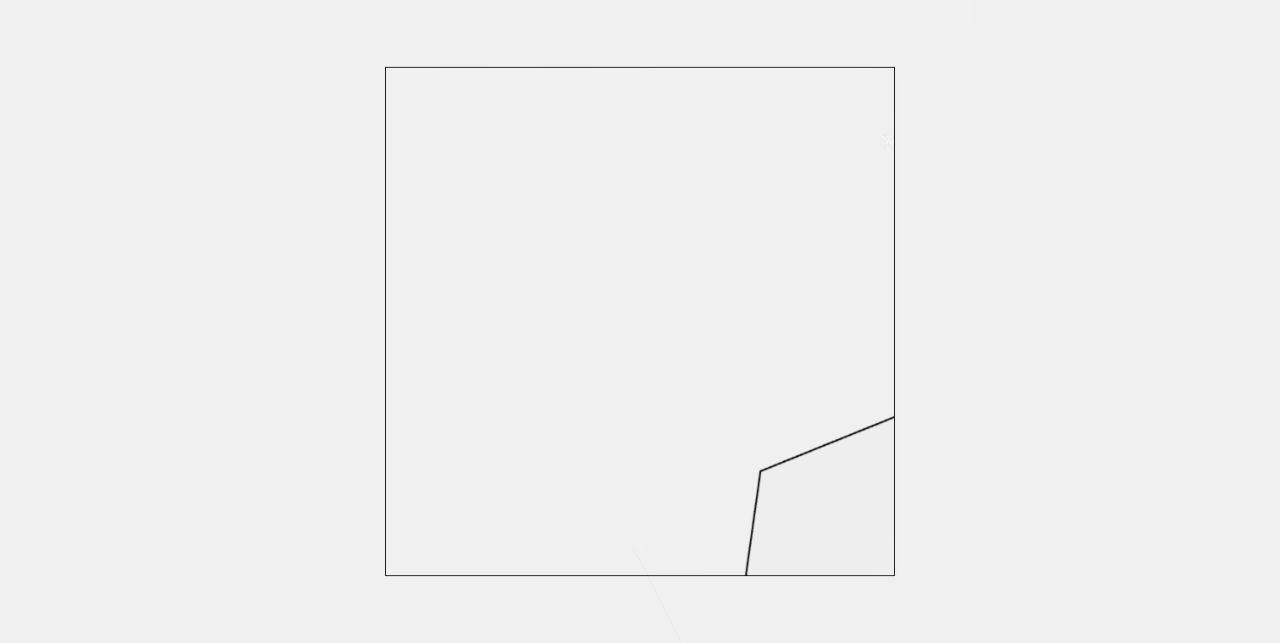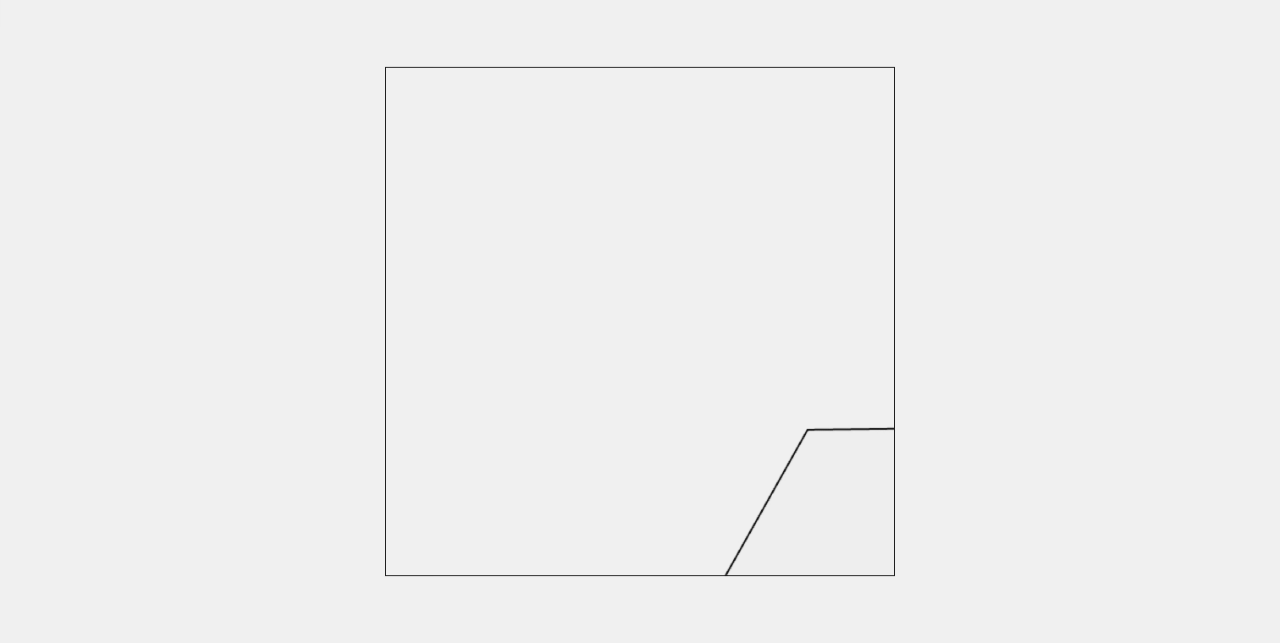
Gemini 2.5 Pro
六边形正确生成,但是没有生成小球

Kimi K2
物理规律还行,不过六边形没有旋转。再给 kimi 一次机会,可以正确做对


DeepSeek R1
物理规律还行,不过后面小球跳出六边形还是算失败了。给 deepseek 第二次机会,物理规律依然还不错,但是球还是跳出六边形了

豆包
基本符合预期
⚡ Triton 算子编写测试案例
🎯 测试Prompt:
请你用 Triton 从零实现一个与 torch.nn.functional.layer_norm 完全等价的前向算子,并编写相应的测试与基准验证脚本。
- 实现 layernorm_triton(x, weight, bias, eps=1e-5),与 torch.nn.functional.layer_norm(x, [x.size(-1)], weight, bias, eps) 在数值上逐元素一致(CUDA 张量输入/输出)
- 主函数中测试多组输入形状 (使用 [32,1024]、[64,4096]、[8,16384])及三种数据类型:float32、float16、bfloat16,打印绝对误差和相对误差,判断实现是否正确(验证 max_abs_error < 2e-2,mean_abs_error < 1e-2)
- 主函数中同时测量在形状 [64,4096] 输入下,分别调用 Triton 实现与 PyTorch 原生 layer_norm 各 100 次的平均耗时(使用 torch.cuda.Event)
- 所有代码写到一个脚本里,结果打印尽量简洁
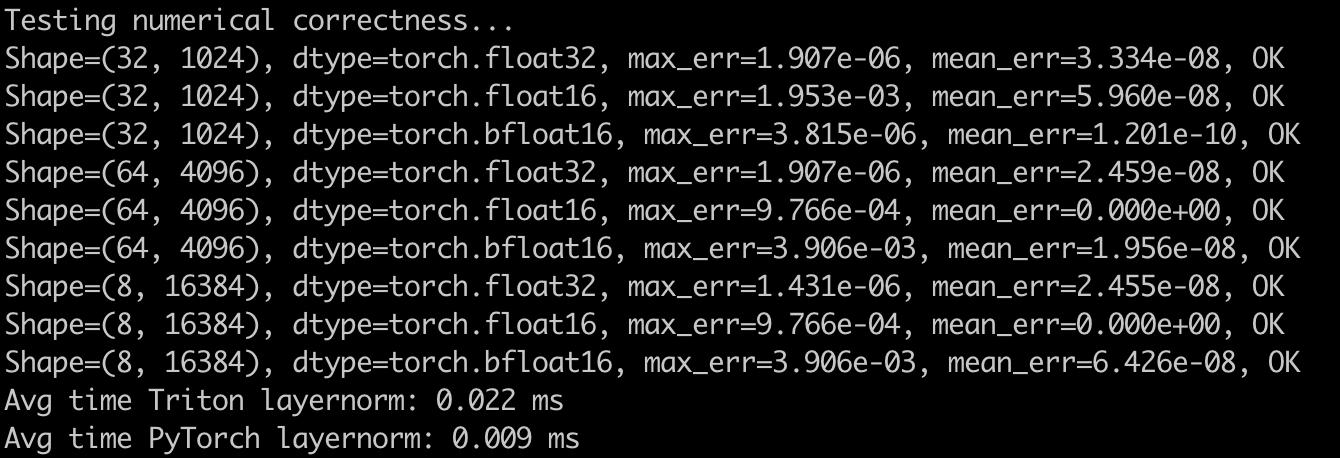
GPT o4-mini-high
生成代码完成度(算子实现、测试样例)和正确性都符合预期。(毕竟 Triton 是 OpenAI 开发的,要是这都写不出来就有点尴尬了...)
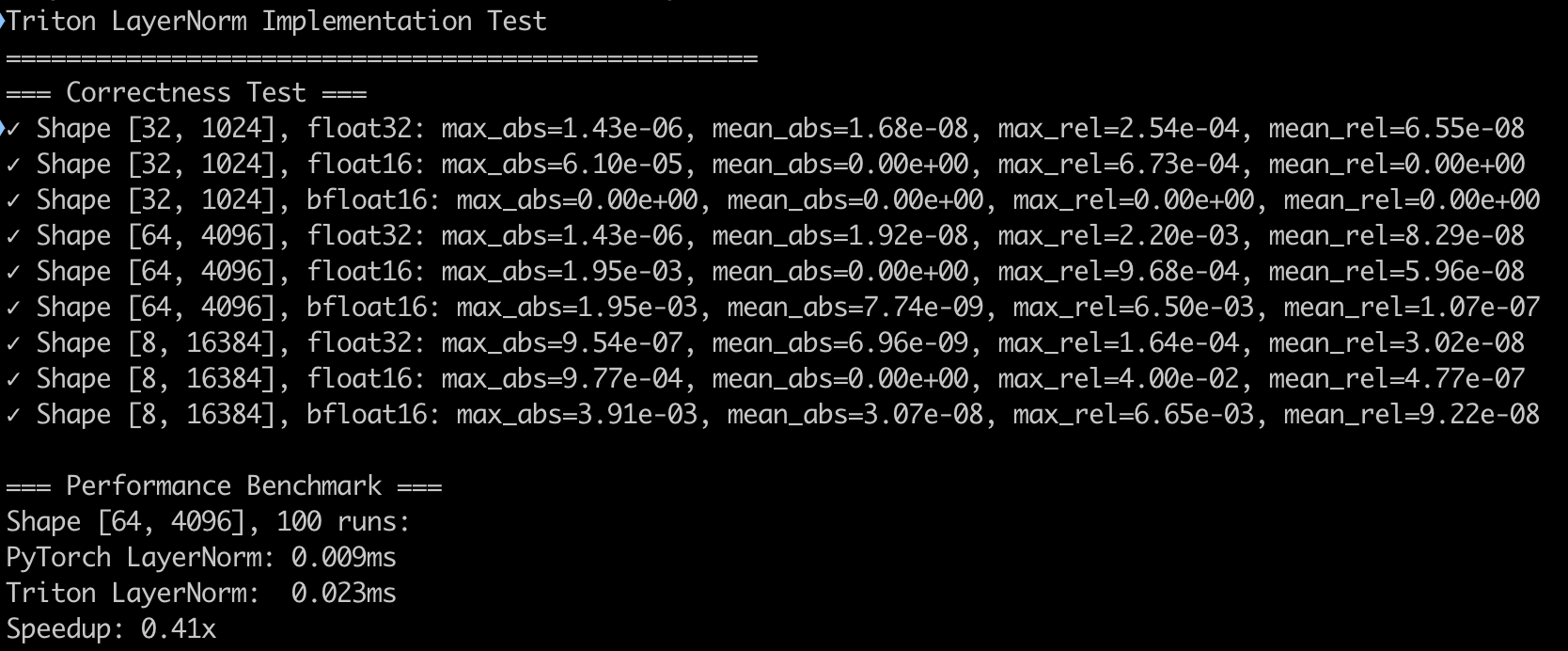
Claude Sonnet 4
能正确完成
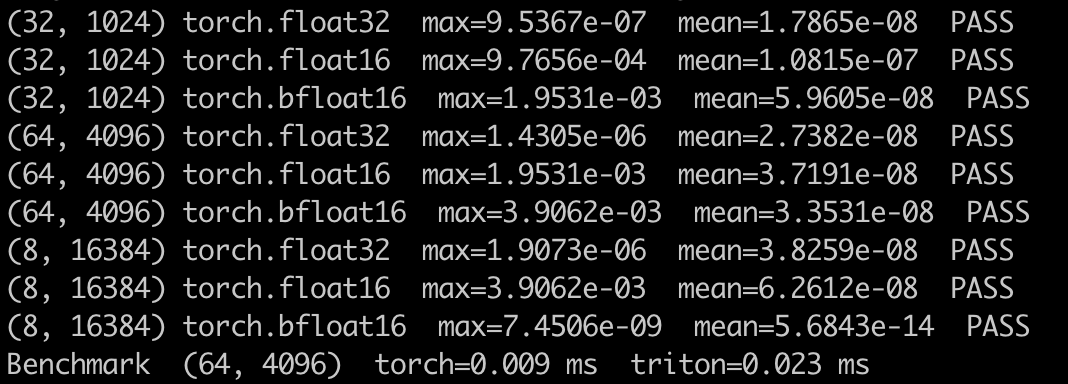
Kimi K2
可以正确完成
Qwen3-235B-A22B
第一次运行遇到报错:AttributeError: module 'triton' has no attribute 'next_power_of_two'. Did you mean: 'next_power_of_2'?
将报错给 Qwen 后重新写,还是没有修复:AttributeError: module 'triton.language' has no attribute 'next_power_of_2'
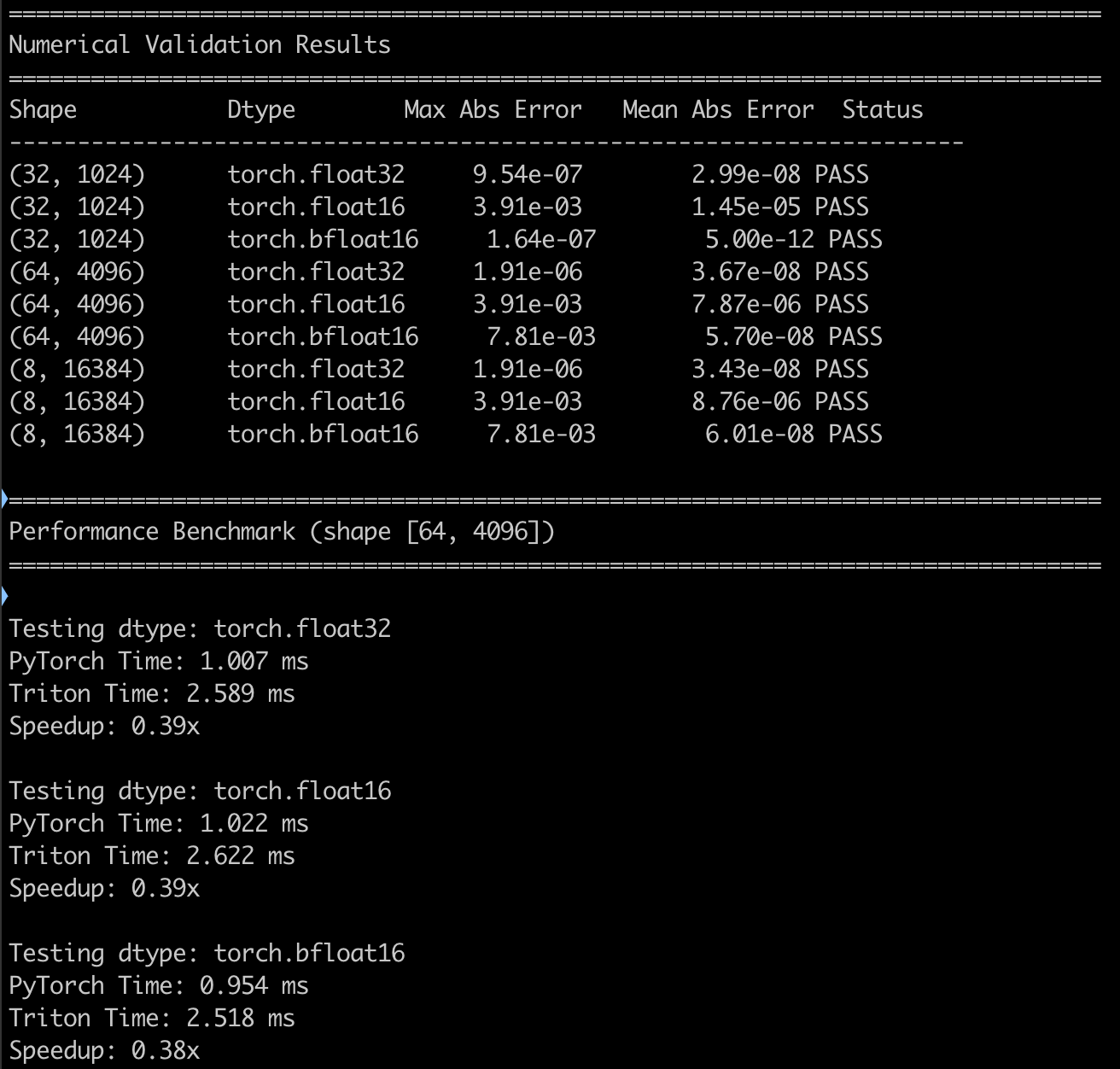
DeepSeek R1
第一次运行报错:ValueError: too many values to unpack (expected 2)
第二次运行正确
📈 模型能力总结对比
| 模型名称 | 算法能力(LiveCodeBench) | 工程能力(SWE-Bench) | 小球物理模拟 | Triton 算子实现 | 总体表现简评 |
|---|---|---|---|---|---|
| Claude Sonnet 4 | ✅优秀 | ✅优秀 | 工程能力最强,综合表现非常稳定 | ||
| GPT-4o | ❌失败 | ✅优秀 | 算法能力最强,但偶尔会出现行为偏差 | ||
| GPT o4-mini-high | ✅良好 | ✅优秀 | 表现稳定,生成代码质量高 | ||
| Gemini 2.5 Pro | ❌未生成小球 | ✅(有一定能力) | 知识储备丰富,但在物理模拟中稍弱 | ||
| Kimi K2 | ✅良好(需重试) | ✅(可完成) | 可用性较高,第二次生成成功率更高 | ||
| Deepseek R1 | ❌物理出界 | ✅(需重试) | 性能尚可,但稳定性略差 | ||
| 豆包 | ✅良好 | 未测试 | 工程能力出色,小模型中表现优秀 | ||
| Qwen3-235B | 未测试 | ❌调用报错 | 有潜力,但细节实现不够稳健 |
🎓 结语
🎯 如何挑选适合的大模型
- 查看公开 benchmark 榜单:找性能最好的模型
- 构造技术领域测试样例:简单测试确认模型性能
- 多模型组合使用:不同场景选择最优模型
💡 主流模型选择经验
- Claude 4 Opus/Sonnet:写代码第一选择,工程能力强,使用范围广
- GPT o3:算法能力强,难度很高的某些代码只有 GPT o3 能写出来,比如根据论文中提出的新方案公式来实现对应的代码
- Gemini 2.5 Pro:知识储备大,长文本能力强,跨模态理解需求
- 国内模型:目前 DeepSeek R1 和 Kimi K2 算是代码能力偏强的一档,但是和 Claude 模型还有一定差距
不同的大模型侧重点不一样,所以不同的技术领域最优的大模型可能是不同的,最好能同时使用多个大模型。结合 benchmark 榜单和自定义测试,是评估模型真实可用性的最佳方式(榜单不完全可信,还是需要自己验证)。
现阶段一定有人能解决但是所有大模型都无法解决的难题,我们需要提前了解大模型的能力边界。但是一定要相信,这些问题未来大模型一定能支持。大模型的能力迭代速度远快于人的学习提升速度。